发布日期:2024-08-16 11:25 点击次数:77

 淫色
淫色
剪辑:剪辑部
Nature的一篇著作露馅:你发过的paper,很可能仍是被拿去历练模子了!有的出书商靠卖数据,仍是狂赚2300万好意思元。关联词辛贫窭苦码论文的作者们,却拿不到一分钱,这合理吗?
民众数据告急,怎样办?
论文来凑!
最近,Nature的一篇著作向咱们揭露了这么一个事实:连科研论文,齐被薅去训AI了……

据悉,许多学术出书商,仍是向科技公司授权拜访自家的论文,用来历练AI模子。
一篇论文从酝酿idea到成稿,包含了些许作者昼日日夜的心血,如今很可能在不知情的情况下,就成为训AI的数据。
这合理吗?

更可气的是,我方的论文还被出书商拿来牟利了。
根据Nature申报,上个月英国的学术出书商Taylor & Francis仍是和微软签署了一项价值1000万好意思元的左券,允许微软获取它的数据,来雠校AI系统。
而6月的一次投资者更新骄贵,好意思国出书商Wiley允许某家公司使用其本色训模子后,径直一举豪赚2300万好意思元!
但这个钱,跟遍及论文的作者是半毛钱干系齐莫得的。

何况,华盛顿大学AI说合员Lucy Lu Wang还暗示,即使不在可盛开获取的存储库内,任何可在线阅读的本色,齐很可能仍是被输入LLM中。
更可怕的是,如果一篇论文仍是被用作模子的历练数据,在模子历练完成后,它是无法删除的。
如果当今,你的论文还尚未被用于历练AI,那也无谓驰念——它应该很快就会了!
数据集如黄金,各大公司纷纷出价
咱们齐知说念,LLM需要在海量数据上进行历练的,而这些数据经常是从互联网上持取的。
恰是从这些历练数据中数十亿的token中,LLM推导出模式,从而生成文本、图像、代码。
而学术论文篇幅又长,信息密度又高,彰着等于能喂给LLM的最有价值的数据之一。
何况,在无数科学信息上历练LLM,也能让它们在科学主题上的推贤慧力大大提高。
Wang仍是共同创建了基于8110万篇学术论文的数据集S2ORC。滥觞,S2ORC数据集是为了文本挖掘而开辟的,但其后,它被用于历练LLM。
2020年非渔利组织Eleuther AI构建的Pile,是NLP说合中应用最无为的大型开源数据集之一,总量达到800GB。其中就包含了无数学术来源的文本,arXiv论文比例为8.96%,此外还涵盖了PubMed、FreeLaw、NIH等其他学术网站。

前段时间开源的1T token数据集MINT也挖掘到了arXiv这个矿藏,共索要到了87万篇文档、9B token。
从底下这张数据贬责历程图中,咱们就能发现论文数据的质地有多高——简直不需要太多的过滤和去重,使用率极高。

而当今,为了嘱咐版权争议,各大模子公司也开动真金白银地出价,购买高质地数据集了。
本年,「金融时报」仍是把我方的本色以突出可不雅的价钱,卖给了OpenAI;Reddit也和谷歌达成了访佛的左券。
而以后,这么的来去也少不了。
诠释注解论文曾被LLM使用,难度极高
有些AI开辟者会盛开我方的数据集,但许多开辟AI模子的公司,会对大部分历练数据守秘。
Mozilla基金会的AI历练数据分析员Stefan Baack暗示,关于这些公司的历练数据,谁齐不知说念有什么。
而最受业内东说念主士接待的数据来源,无疑等于开源存储库arXiv和学术数据库PubMed的摘要了。
现时,arXiv仍是托管了高出250万篇论文的全文,PubMed包含的援用数目更是惊东说念主,高出3700万。
天然PubMed等网站的一些论文全文有付费墙,但论文纲如若免费浏览的,这部分可能早就被大科技公司持取干净了。

是以,有莫得本领程序,能识别我方的论文是否被使用了呢?
现时来说,还很难。
伦敦帝国理工学院的盘算推算机科学家Yves-Alexandre de Montjoye先容说念:要诠释注解LLM使用了某篇笃定的论文,是很艰苦的。
有一个想法,是使用论文文本中相配凄惨的句子来教导模子,望望它的输出是否等于原文中的下一个词。

有学者曾以「哈利·波特与魔法石」第三章的开始教导GPT-3,模子很快正确地吐出了节略一整页书中的本色
如果是的话,那就没跑了——论文就在模子的历练网络。
如果不是呢?这也随机是有用凭证,能诠释注解论文未被使用。
因为开辟者可以对LLM进行编码,让它们过滤反映,从而不和历练数据过于匹配。
可能的情况是,咱们费了老大劲,依然无法明确地诠释注解。
另一种程序,等于「成员推理挫折」。

这种程序的旨趣,等于当模子看到过去见过的东西时,会对输出更有信心,

为此,De Montjoye的团队有益开辟了一种「版权陷坑」。
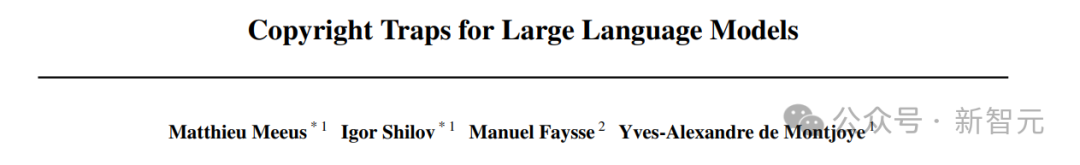
为了配置陷坑,团队会生成看似合理却无真理真理的句子,并将其荫藏在作品中,比如白色布景上的白色文本或网页上骄贵为零宽度的字段。
如果模子对未使用的限度句的困惑度,比对荫藏在文本中的限度句的困惑度更高,这就可以当作陷坑曾被看到的统计凭证。

版权争议
关联词,即使能诠释注解LLM是在某篇论文上历练的,又能怎样办呢?
这里,就存在一个由来已久的争议。
在出书商看来,如果开辟者在历练中使用了受版权保护的文本,且莫得赢得许可,那铁定等于侵权。
但另一方却可以这么反驳:大模子并莫得抄袭啊,是以何来侵权之说?

简直,LLM并莫得复制任何东西,它仅仅从历练数据中获取信息,拆解这些本色,然后运用它们学习生成新的文本。
天然,这类诉讼仍是有前例了,比如「纽约时报」对OpenAI那场震天动地的告状。
其中愈加复杂的问题,是怎样划清商用和学术说合用途。
根据现时arXiv网站上的使用条件,如果是个东说念主或说合用途,持取、存储、使用扫数的电子预印本论文和网站元数据齐是合规且被提拔的。

关联词,arXiv对交易方面的使用是严令不容的。
那么问题来了,如果某个交易公司使用了学术机构发布的开源数据集历练我方的交易模子,且数据来源含有arXiv或访佛学术出书机构,这怎样算?
此外,出书商在用户的订阅条件中经常也莫得明确章程,能否将论文用作模子的历练数据。
比如,一个付费购买Wiley论文库阅读全文履历的用户,是否被允许将这些文本拷贝下来喂给模子?
当今的问题是,有东说念主思让我方的作品纳入LLM的历练数据中,有东说念主不思。

有东说念主仍是作念出来一个[haveibeentrained」的同名网站,用来检测我方的本色是否被用于历练AI模子
比如Mozilla基金会的Baack就暗示,相配乐于看到我方的作品让LLM变得更准确,「我并不珍摄有一个以我的格调写稿的聊天机器东说念主」。
然而,他只可代表我方,依然有其他许多艺术家和作者,会受到LLM的挟制。
如果提交论文后,这篇论文的出书商决定出售对版权作品的拜访权限,阿谁别的论文作者是根柢莫得职权插手的。
通盘圈子亦然鱼龙混合,公开辟表的著作既莫得既定的程序来分派来源,也无法笃定文本是否已被使用。
包括de Montjoye在内的一些说合者对此感到颓丧。
「咱们需要LLM,但咱们仍然但愿有公道可言,但现时咱们还莫得发明出理思的公道是什么风景。」
多模态数据不够,arXiv来凑
事实上,弘大的arXiv论文库中,可以运用的不啻文本数据。
ACL 2024吸收了一篇来自北大和港大学者的论文,他们尝试运用这些论文中的图文构建高质地多模态数据集,取得了相配可以的终结。

前段时间,纽约大学谢赛宁栽种和Yann LeCun等东说念主发布的Cambrian模子也用到了这个数据集。

之是以要用arXiv论文中的图片,主要如故由于科学界限历练数据集的稀缺。
GPT-4V等视觉话语模子天然在天然场景的图像中有出色的发达,但在解释概括图片方面,比如几何形势和科学图表,依旧智力有限,也无法蚁集学术图片中渺小的语义隔离。
这篇论文构建的多模态arXiv数据集系数用到了各个STEM界限的57.2万篇论文,高出arXiv论文总和(2.5M)的五分之一,包含两部分:问答数据集ArXivQA和图片标注数据集ArXivCap。

依托arXiv无数且各样的论文收录,与之前的科学图片数据集比拟,ArXivCap的数据量是第二名SciCap的3倍,ArXivQA亦然惟一涵盖无为界限内委果论文的问答数据集。

通过使用这些界限特定数据进行历练,VLM的的数学推贤慧力有了显赫增强,在多模态数学推理基准上罢了了10.4%的准确率晋升。
比如,在ArXivQA上历练过的Qwen 7B模子约略正确蚁集条形图并呈文关联问题(左图),数学智力也有所提高(右图)。不仅谜底正确,给出的推理过程也愈加完好充分。
数据集构建
数据集的构建活水线如下图所示。由于arXiv是预印本平台,是以需要先通过发表记载筛选出被期刊或会议吸收的论文,以保证数据质地。
索要论文中的图片-翰墨对并进行基于章程的计帐后,构成ArXivCap;ArXivQA则由GPT-4V生成,但使用了用心想象过的prompt模板。

ArXivCap中的一个单图标注对:

2019年论文「Semigroup models for biochemical reaction networks」
ArXivCap数据网络的一个多图标注对:
精选嫩鲍
2018年论文「Low-Power Wide-Area Networks for Sustainable IoT」
ArXivQA数据集示例:

2020年论文「Skyrmion ratchet propagation: Utilizing the skyrmion Hall effect in AC racetrack storage devices」
评估
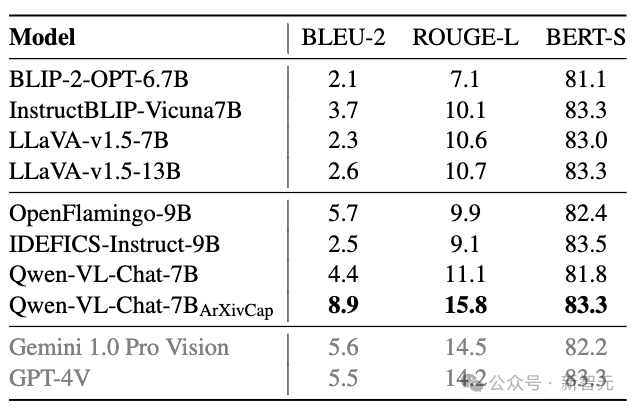
根据在MathVista数据集上的终结,ArXivCap和ArXivQA共同晋升了Qwen-VL-Chat的举座性能,突出了Bard的发达。

最好终结以粗体骄贵,次佳终结以下划线标识
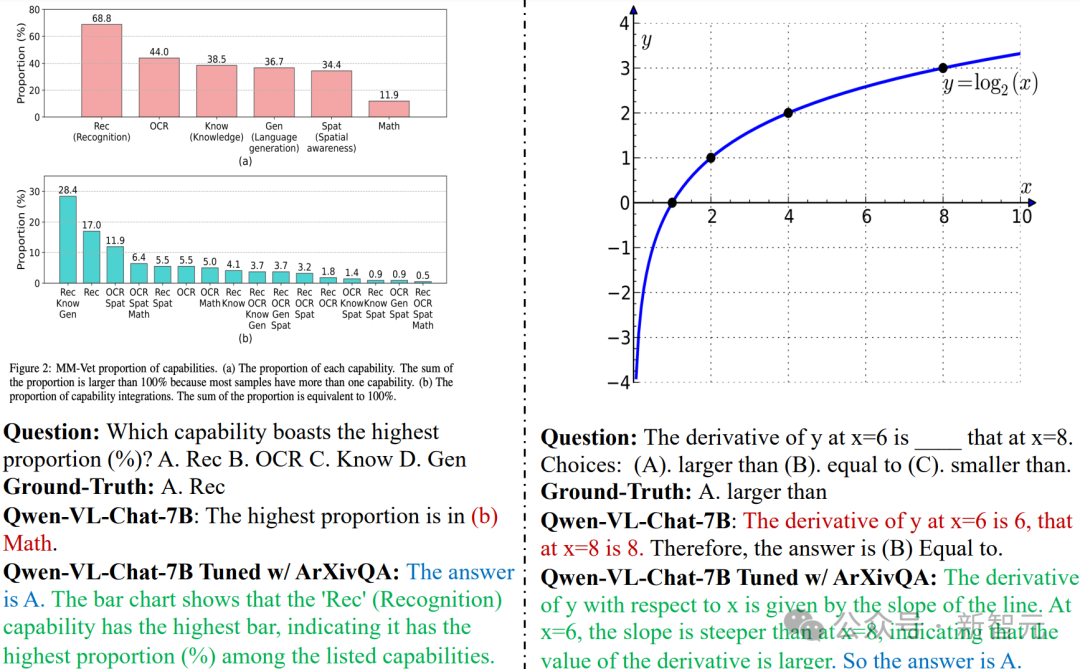
在为单张图片生成图注的任务中,晋升终结愈加显赫,经过ArXivCap历练的Qwen 7B模子可以匹配致使高出GPT-4V。
灰色终结由数据网络500个样本的测试得到
论文提倡了三个新界说任务:多图的图注生成、高下文中的图注生成以及标题生成。经过ArXivCap历练的Qwen 8B的扫数分数齐高出了GPT-4V,且多数情况下是最好终结。

最好终结以粗体骄贵
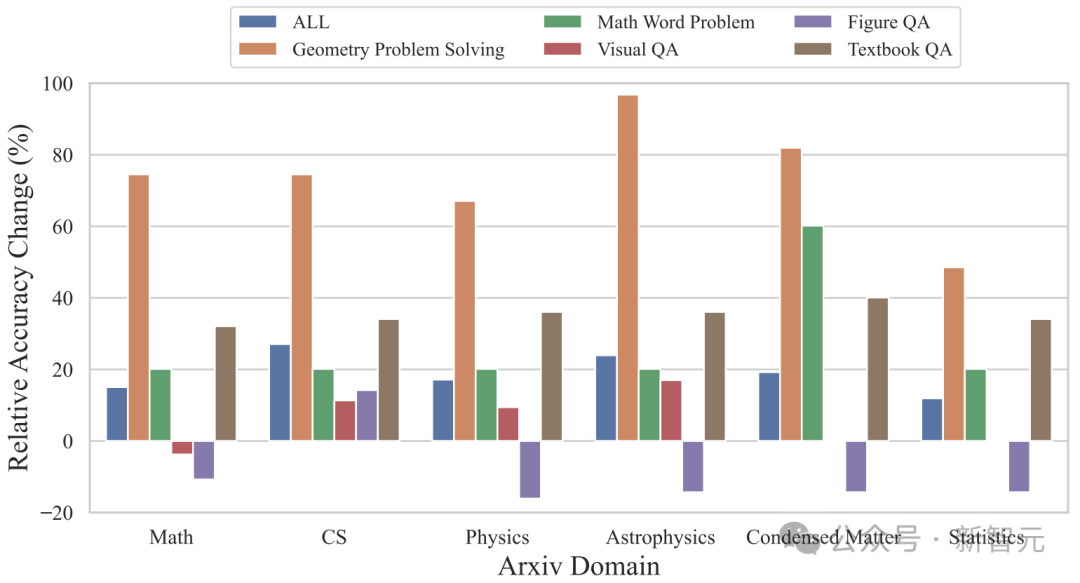
按照说合界限分袂,ArXivQA数据集上的历练在天体物理、凝合态物理、数学、盘算推算机科学这些界限齐能带来突出显赫的晋升,高出60%,准确率变化比例高出60%。
东说念主工评估
前边所述的文本生成质地和准确率齐是基于算法的自动评估,说合团队还对单图的图注生成任务进行了东说念主工评估,但只专注于盘算推算机科学界限的论文。

与前边的基准测试终结比拟,东说念主工评估的终结并不睬思,100个案例中只消16%被以为是「可继承的」,「高下文误读」的问题相对严重,也有一定比例的「过度简化」和「识别作假」。
